
Embora o modelo para o filtro utilizado seja normalmente constituído só de pólos, o sinal de voz nem sempre é bem caracterizado por filtros deste tipo (principalmente quando o som é nasalado). Porém, se u[n] representar a função escalão unitário, repare-se:
| h[n] | = | anu[n] | |
| H(z) | = | 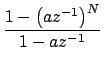 = =  |
|
1 - az-1 = 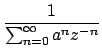 |
Indicando que um zero pode ser visto como um número infinito de pólos (ou aproximado por um número finito). Por esta razão, um filtro só de pólos constitui uma aproximação razoável, desde que se use um número suficiente de pólos. Em média, o espectro da fala contém um pólo por kHz e, na prática, um filtro com um pólo por cada kHz na frequência de amostragem (normalmente soma-se mais um par de pólos extra) resulta razoavelmente bem. O sistema GSM usa uma aproximação de 8 pólos (para uma frequência de amostragem de 8kHz).
2003-11-27